Table of Contents
NVIDIA GTC 2026: Key Announcements, Vera Rubin & What to Buy
Last verified: May 2026. Vera Rubin specs and Blackwell availability confirmed against NVIDIA's GTC 2026 keynote, official product datasheets, and bizon-tech.com.
According to NVIDIA's GTC 2026 keynote, the Vera Rubin VR200 delivers 50 PFLOPS of FP4 compute and a 3.3x throughput jump over the B300. That announcement dominated the conference. Packing 288 GB of HBM4 and 22 TB/s of memory bandwidth, the VR200 represents one of NVIDIA's largest recent generational jumps in AI inference throughput. Three other shifts move money this year, however.
Per NVIDIA's GTC 2026 event announcements, the conference ran March 16 to 19 at SAP Center in San Jose with over 30,000 attendees. Three announcements directly affect your next hardware purchase. Vera Rubin's architecture timeline frames the upgrade window, and the B300's production availability through system integrators like BIZON unlocks the Blackwell tier today. A maturing software stack of NIM, TensorRT-LLM, and NeMo makes deploying models on NVIDIA hardware easier than the prior cycle.

NVIDIA GTC 2026 keynote with Jensen Huang unveiling Vera Rubin's GPU architecture
Key Takeaway
Buy Blackwell now. The RTX 5090, RTX PRO 6000, and B300 SXM cover every buyer profile this year. Vera Rubin datacenter GPUs ship H2 2026 for hyperscalers only. Based on prior NVIDIA release cadence, workstation-class variants typically trail datacenter GPUs by two to four quarters and remain unconfirmed. Don't pause a Q1 to Q2 procurement cycle for an unpriced future GPU.
Jensen Huang's full GTC 2026 keynote walks Vera Rubin's architecture in detail, including the FP4 throughput math and HBM4 bandwidth claims in this article. The Blackwell production update covers what's shipping now versus what waits for H2 2026. It's all there. The agentic AI stack section frames where NIM, TensorRT-LLM, and the NVIDIA OpenShell runtime fit alongside the hardware. For buyers, the keynote is the canonical source on architectural trade-offs.
Jensen Huang (NVIDIA CEO) delivering the GTC 2026 keynote covering Vera Rubin, Blackwell production, and the agentic AI stack. NVIDIA channel.
This article covers each of those highlights, maps the GPU roadmap through 2027, and gives a direct verdict on Blackwell now versus wait. Each section delivers the spec context and the buyer verdict together. You can jump to whichever piece matches your procurement timeline. For GPU-specific recommendations by model size and workload, see our Best GPU for LLM Training & Inference guide.
The Vera Rubin Architecture
Vera Rubin is NVIDIA's successor to Blackwell, with full specs landed at GTC 2026. HBM4 is the key differentiator. According to NVIDIA's announced specs, the VR200 GPU packs 288 GB of HBM4 memory and delivers approximately 50 PFLOPS of FP4 compute. It uses 6th-generation NVLink and is designed from the ground up for multi-node inference and agentic AI pipelines at datacenter scale.

Vera Rubin VR200 vs Blackwell B300, a 3.3x compute jump with 2.8x more memory bandwidth
Per NVIDIA's Blackwell datasheets, the B300 delivers 15 PFLOPS of FP4 on 288 GB HBM3e. NVIDIA's announced VR200 specs match that memory footprint but push theoretical FP4 to 50 PFLOPS, 5x the B200. NVIDIA reports HBM4 bandwidth of 22 TB/s, 2.8x Blackwell's 8 TB/s, and the 3nm Vera Rubin die packs 336 billion transistors. NVIDIA projects a 10x cut in AI inference cost. HBM4 changes the math.
| GPU | Architecture | VRAM | Memory BW | FP4 Compute | Availability |
|---|---|---|---|---|---|
| H200 SXM | Hopper | 141 GB HBM3e | 4,800 GB/s | N/A (FP8 approx 4 PFLOPS) | Now |
| B200 SXM5 | Blackwell | 192 GB HBM3e | 8,000 GB/s | ~9 PFLOPS | Now |
| B300 SXM | Blackwell Ultra | 288 GB HBM3e | 8,000 GB/s | ~15 PFLOPS | Now (Jan 2026) |
| VR200 (Vera Rubin) | Vera Rubin | 288 GB HBM4 | 22,000 GB/s | 50 PFLOPS (inference) / 35 PFLOPS (training) | H2 2026 (datacenter) |
Methodology note: Vera Rubin figures from NVIDIA's GTC 2026 keynote (Jensen Huang, March 17, 2026). Hopper and Blackwell specs from NVIDIA datasheets for H200, B200, and B300 SXM. FP4 figures are non-sparse peak theoretical throughput. Datacenter Vera Rubin is confirmed for H2 2026, with workstation variants unconfirmed.
"The Vera Rubin VR200 delivers 50 PFLOPS of FP4 compute and 22 TB/s of memory bandwidth, a 3.3x compute leap over the B300 on the same 288 GB memory footprint. Hyperscalers get it in H2 2026. Workstation buyers wait."
NVIDIA confirmed Vera Rubin datacenter deployments for H2 2026 only. Neither workstation nor server options are confirmed for the BIZON customer profile, since prior NVIDIA cadence shows these product tiers typically trail datacenter releases by two to four quarters. Plan around what ships today. No announced roadmap slide justifies a procurement freeze.
Blackwell: What You Can Buy Now
NVIDIA's Blackwell lineup spans four GPU tiers from the RTX 5090 up to the B300 SXM, all shipping now. Consumer, professional, and enterprise SXM Blackwell all ship in volume alongside the still-production H200, with system integrators having ramped production since Q1 2026. Every buyer profile has a current-generation option available today. Stock backs every tier.
Consumer Blackwell - The RTX 5070 Ti and 5080 (both 16 GB), plus the RTX 5090 (32 GB), are all available at retail. The RTX 5090 wins here. FP4 matters for throughput. It runs 70B-parameter models at Q4 quantization and supports native FP4 through the Blackwell architecture.
Professional Blackwell - The RTX PRO 6000 Blackwell (96 GB GDDR7 ECC) is now shipping. It's the first workstation GPU with 96 GB of memory. LLaMA 3.3 70B-class models at Q8 precision run on a single card, no quantization trade-offs. For users who need full-weight inference without splitting across GPUs, this is the card.
Enterprise Blackwell - The B200 (192 GB HBM3e) and B300 (288 GB HBM3e) are available through BIZON and other system integrators, with the B300 shipping since early 2026. Our water-cooled chassis hold sustained clocks through multi-day runs where air-cooled designs may throttle. The H200 (141 GB HBM3e) remains a widely deployed enterprise LLM GPU.
| GPU | VRAM | Tier | Best For |
|---|---|---|---|
| RTX 5090 | 32 GB GDDR7 | Consumer | Local inference up to 70B (Q4), LoRA fine-tuning |
| RTX PRO 6000 Blackwell | 96 GB GDDR7 ECC | Professional | 70B at Q8 (no quantization trade-offs), 120B+ MoE at Q4, professional workloads |
| B200 SXM5 | 192 GB HBM3e | Enterprise | Production training, frontier inference |
| B300 SXM | 288 GB HBM3e | Datacenter | Full DeepSeek R1 (2 cards), pre-training at scale |
Methodology note: VRAM, memory type, and architecture details are sourced from NVIDIA's official Blackwell product pages. Enterprise SXM configuration details live on BIZON product pages at bizon-tech.com.
Software Stack and Agentic AI Releases
NVIDIA's new Dynamo inference layer delivers up to 7x throughput per GPU for DeepSeek R1 on GB200 NVL72. It disaggregates prefill and decode, routing each to its optimal hardware. The result is higher utilization under real multi-user request loads. That matters at scale. Dynamo integrates natively with TensorRT-LLM, vLLM, and SGLang, so the efficiency gain runs on existing Blackwell hardware.
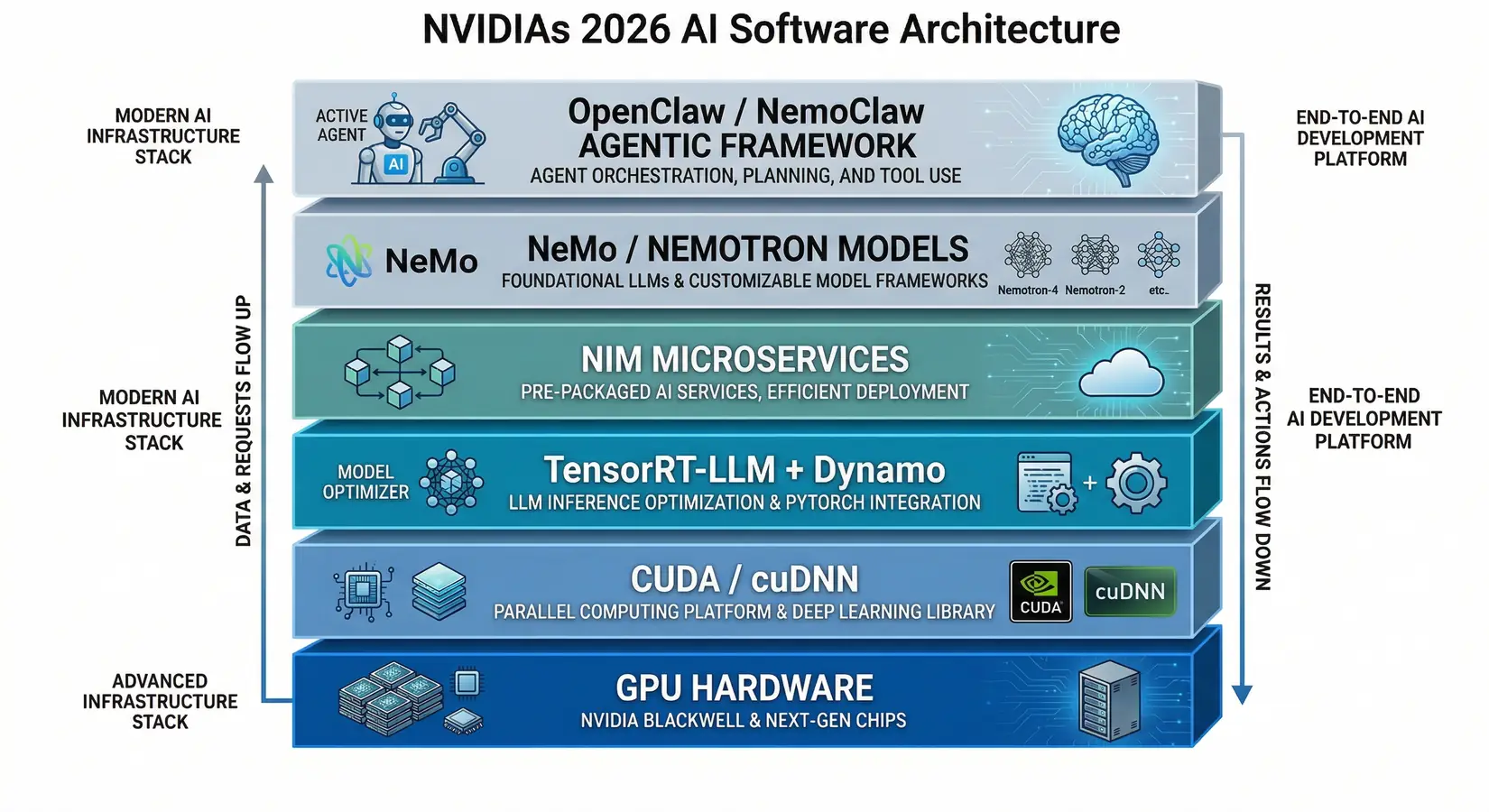
NVIDIA's 2026 AI software stack from CUDA and Dynamo to the OpenClaw agentic framework
NVIDIA NIM (Inference Microservices) continued its expansion at GTC 2026. NIM provides pre-packaged, optimized inference containers that let enterprise teams deploy LLMs on NVIDIA hardware without manual optimization. At GTC, NIM was showcased as a core component of the new agentic AI stack, powering infrastructure for autonomous agent deployment alongside the OpenClaw platform.
TensorRT-LLM received major updates for Blackwell. Beyond the headline throughput number, the value is in KV-cache reuse across requests and disaggregated serving across long-context inference clusters. Faster and cheaper per token, in other words. Speed and cost improve together.
NVIDIA's NeMo and Nemotron received major updates. The Coalition rallies partners around frontier model families including Cosmos, Isaac GR00T, and the open Nemotron 3 omni-understanding models. Open weights ship now. BIZON customers run them on their own hardware.
Agentic AI infrastructure was the dominant keynote theme. Per NVIDIA's announcement, NVIDIA NemoClaw installs the NVIDIA OpenShell runtime and Nemotron models in one command, adding security and privacy controls for OpenClaw agents. Partners include Adobe, Atlassian, Salesforce, and ServiceNow.
GPU-accelerated data science expanded at GTC 2026. DuckDB, Snowflake, Databricks, and Apache Spark announced GPU-native processing integrations with NVIDIA RAPIDS. GPU acceleration now happens at the query and transform layer, not just model training. For GPU hardware guidance for ETL and ML pipelines, see our Best GPU for Data Science guide.
The NVIDIA GPU Roadmap
NVIDIA's roadmap matters because each generation's headroom decides how long today's purchase pays back. Four architectures in five years sets the buyer cadence. Hopper anchored production AI in 2022, Blackwell carries workstations and frontier training well past 2025, and the Rubin architecture extends the datacenter roadmap to H2 2026 for hyperscaler buyers. That cadence decides your upgrade window.
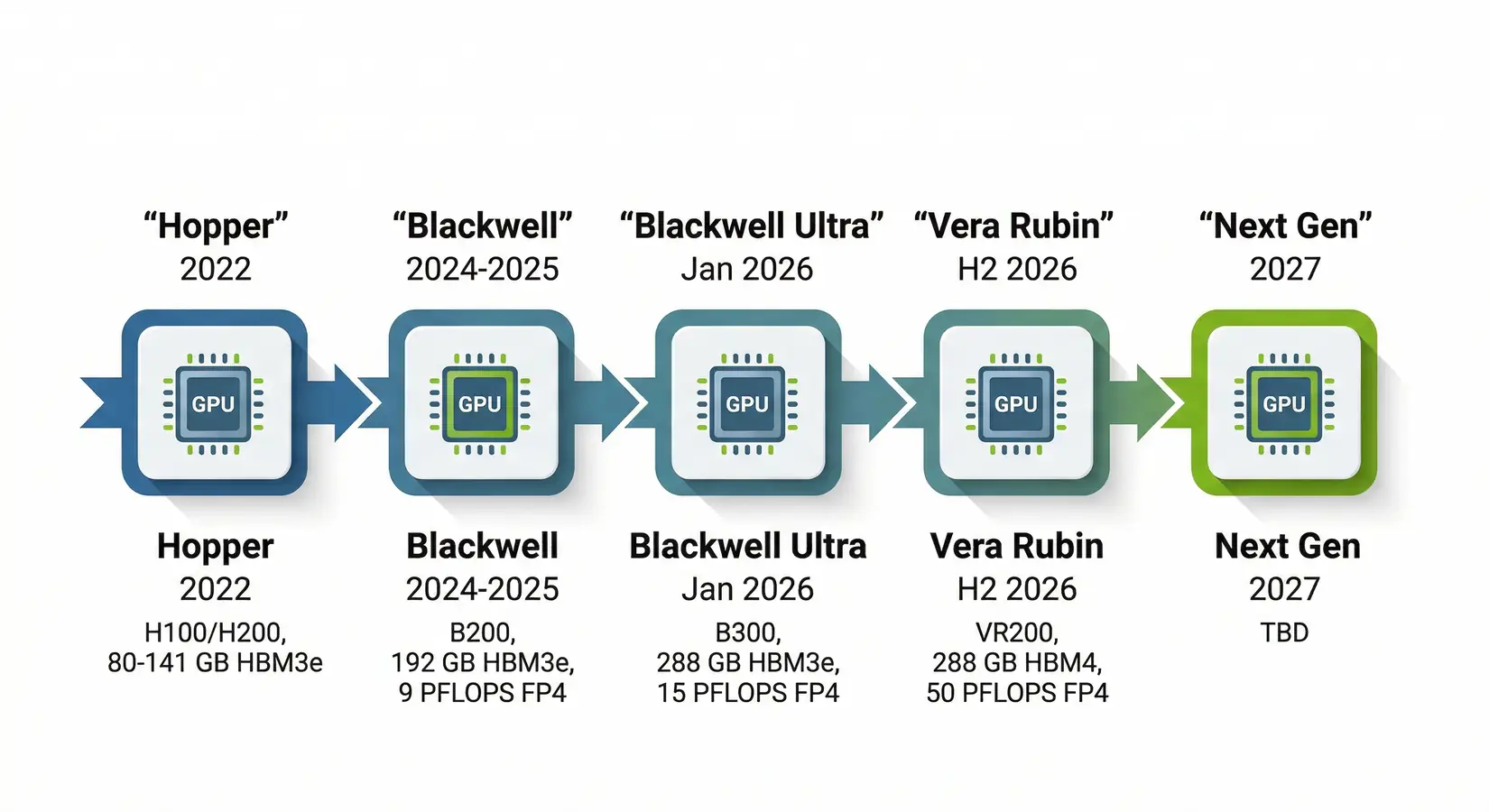
NVIDIA GPU architecture timeline from Hopper (2022) through Vera Rubin (H2 2026) and beyond
NVIDIA has shipped four GPU architectures in five years. That is a fast cadence. The RTX 5090 launched in 2024 and Blackwell-class silicon will carry the buyer's window through at least 2027. Blackwell is a 2 to 3 year platform, not a transition chip. Buy now and run. The RTX 5090, B200, and B300 handle production workloads well into 2028.
Buy Blackwell Now or Wait?
Four out of five buyer profiles should buy Blackwell now. Only enterprise datacenter teams have reason to wait, since their Rubin window opens Q3 to Q4 2026 while workstation availability for that architecture hasn't been announced. Blackwell is the current generation, not the transition chip. Buy it for production today and plan the next upgrade as a separate cycle in 2027.

Buy now vs wait decision guide by buyer profile for Blackwell and Vera Rubin
Watch Out
Don't wait for a "Vera Rubin RTX" workstation card. NVIDIA has not announced a consumer or professional Vera Rubin variant.
| Buyer Profile | Verdict | Reason |
|---|---|---|
| Researcher / developer (workstation) | Buy now | Vera Rubin workstation GPUs are TBD. RTX 5090 and RTX PRO 6000 cover 2026 workloads well. |
| Startup / SME (single server) | Buy now | B200 and B300 systems are available and production-ready. No confirmed Vera Rubin server timeline. |
| Enterprise datacenter (Q1 to Q2 2026 budget) | Buy now | B300 is the best available option. Don't pause procurement for an unpriced future GPU. |
| Enterprise datacenter (Q3 to Q4 2026 budget) | Consider waiting | Vera Rubin datacenter GPU may be available. Get on waitlist and evaluate when specs and configurations are confirmed. |
| Anyone waiting for Vera Rubin workstations | Buy now | Retail Vera Rubin availability is not confirmed. Could be 2027. Don't wait on rumor. |
Four of five buyer profiles land in the same place. Buy now. Only Q3 to Q4 enterprise datacenter buyers have a credible reason to pause, and even those teams should treat the wait as a parallel evaluation rather than a procurement freeze. Blackwell is in stock and ready to deploy.
Get Started With BIZON Blackwell
We ship every Blackwell system tier, from dual-EPYC rackmount to the eight-GPU B300 HGX server. Every system arrives with the full pre-installed AI stack: Ubuntu, CUDA, cuDNN, PyTorch, TensorFlow, and TensorRT-LLM configured out of the box. Custom water cooling sustains full boost clocks on 4+ GPUs under load. A 3-year warranty backed by lifetime technical support covers the rest.

BIZON Blackwell GPU server lineup from the X7000 to the X9000 G5
From our experience building for research labs and Fortune 500 AI teams, the biggest time sink for in-house GPU deployments isn't the hardware. It's the driver stack, period. BIZON handles a week of CUDA dependency wrangling before the system ships. The unboxing is the start of productive work.
BIZON Advantage
Every BIZON Blackwell build runs real training and inference workloads on our test floor before it ships. Water-cooled chassis hold full Blackwell boost clocks through multi-day runs. That separates production throughput from benchmark numbers.
The four systems below span from dual-socket workstation to eight-GPU HGX server. Entry-level inference pairs with the X7000, while maximum compute density at 120 PFLOPS FP4 lives in the top-tier HGX configuration. Each system supports custom GPU configurations. Teams can start at the right tier and scale without replacing the host stack.

BIZON X7000 G3 Rackmount Server
- Best for: Production LLM training, full fine-tuning 70B+, multi-user inference
- GPUs: Up to eight GPUs (RTX professional + Ada lineup, L40s, A100, H100 NVL, H200 NVL)
- VRAM: Up to 1,128 GB
- CPU: Dual AMD EPYC 9004/9005
- RAM: Up to 3,072 GB DDR5 ECC Buffered
- Connectivity: 10 GbE dual port (two RJ45) integrated, up to 400 Gbps InfiniBand NDR (Mellanox ConnectX-7), NVLink Bridge available for paired GPUs

BIZON ZX9000 Water-Cooled Server
- Best for: Sustained 24/7 inference, thermal-critical deployments
- GPUs: Up to eight water-cooled GPUs (H100 NVL, H200 NVL, RTX PRO 6000 Blackwell)
- VRAM: Up to 1,128 GB
- CPU: Dual AMD EPYC 9004/9005
- RAM: Up to 3,072 GB DDR5 ECC Buffered
- Connectivity: 10 GbE dual port (two RJ45) integrated, up to 400 Gbps InfiniBand NDR (Mellanox ConnectX-7), NVLink Bridge available for paired GPUs

BIZON X9000 G4 HGX Server
- Best for: Frontier model training, full DeepSeek R1/LLaMA 3.1 405B
- GPUs: Eight NVIDIA B200 SXM5 (fixed SXM-only chassis)
- VRAM: 1,536 GB HBM3e
- CPU: Dual AMD EPYC or Dual Intel Xeon Scalable
- RAM: Up to 3,072 GB DDR5 ECC (AMD) or 4,096 GB (Intel)
- Connectivity: 10 GbE dual port (two RJ45), up to 400 Gbps InfiniBand NDR (Mellanox ConnectX-7)

BIZON X9000 G5 HGX Server
- Best for: Maximum compute density available today, 120 PFLOPS FP4 per system
- GPUs: Eight NVIDIA B300 SXM5 (fixed SXM-only chassis)
- VRAM: 2,304 GB HBM3e
- CPU: Dual AMD EPYC or Dual Intel Xeon 6500/6700-Series
- RAM: Up to 3,072 GB DDR5 ECC (AMD) or 4,096 GB (Intel)
- Connectivity: 10 GbE dual port (two RJ45), up to 400 Gbps InfiniBand NDR (Mellanox ConnectX-7)
GTC 2026 Takeaways
Blackwell ships and Vera Rubin does not. The VR200 announcement reshapes the hyperscaler roadmap, leaving the near-term buying decision unchanged for workstation and small-cluster buyers. Blackwell Ultra ships with 288 GB HBM3e and a full stack from CUDA to NIM containers, while Vera Rubin professional tiers remain unannounced. Buy what ships.
BIZON Blackwell systems ship with CUDA, cuDNN, PyTorch, vLLM, and Docker validated before the box leaves the floor. Water-cooled multi-GPU configs hold full clocks where air-cooled builds throttle under sustained load. Thermal margin matters. Each system runs real training and inference workloads on our test floor before it ships.
Configure your Blackwell build through BIZON's deep learning AI workstations for desktop and tower workloads. NVIDIA GPU servers also cover 8x B200, B300, H100, and H200 SXM5 deployment tiers for production teams. Spec the system to today's workload with the headroom to grow into the next architecture, and every tier ships with the full AI stack pre-installed. Water cooling on multi-GPU configs holds sustained Blackwell boost clocks through production-scale runs.
BIZON manufactures the workstations and servers discussed in this article. Product specifications reflect published vendor sources, with system-level details drawn from BIZON build-floor experience and pre-ship validation. Our editorial recommendations follow the workload-first analysis shown above. They are not constrained by inventory or commercial considerations.