Table of Contents
Llama 4 GPU System/GPU Requirements. Running LLaMA Locally
Introduction

Artificial Intelligence (AI) is continuously reshaping our world, and large language models (LLMs) stand at the forefront of this rapid progress. The emergence of LLAMA 4 marks a brand-new era in generative AI—a model that’s more powerful, efficient, and capable of a wider variety of tasks than many of its predecessors. This new iteration represents a significant leap forward in both functionality and accessibility, reflecting years of research and development in natural language processing (NLP) and machine learning frameworks.
In this article, we will explore the features that define LLAMA 4, system and GPU requirements, how it compares to previous versions, and why its capabilities make it a game-changer for developers, researchers, and businesses. We’ll also provide a comprehensive guide on how to set up and run LLAMA 4 locally, giving you hands-on experience with advanced AI modeling on your personal or professional workstation. Finally, we’ll look at how Bizon workstations can provide the specialized hardware you need to make LLAMA 4 run quickly and efficiently—taking the guesswork out of selecting the right system setup.
Whether you are an AI researcher striving for state-of-the-art performance, a software engineer integrating advanced language models into new products, or a hobbyist exploring cutting-edge technology, LLAMA 4 has something to offer. Let’s dive in!
New Features of LLAMA 4
LLAMA 4 focuses on power, adaptability, and ease of use. Here’s a closer look at the standout new features that set this release apart:
1. Larger Model Size and Enhanced Architecture
LLAMA 4 boasts a significantly larger parameter count than its predecessors, enabling it to handle more complex linguistic tasks. The model architecture has been refined to offer improved parallelization, more efficient memory usage, and smoother integration with the latest GPU hardware. As a result, LLAMA 4 has higher accuracy and demonstrates more coherent, context-aware responses in various natural language tasks—ranging from summarizing lengthy documents to interpreting complex instructions.
2. Extended Context Window
One of the most groundbreaking advances in LLAMA 4 is its greatly expanded context window—so extensive that
it has been referred to as having an “infinite context window.” Traditional language models often face
limitations when dealing with lengthy text, leading to loss of context or forced reliance on techniques like
Retrieval-Augmented Generation (RAG). LLAMA 4, however, can directly handle input lengths of up to 10M
tokens (and beyond), making it the first model to offer such a vast capacity. This effectively
eliminates the need for external context retrieval methods and opens the door to a wide range of use cases:
from long-form story generation and exhaustive research analysis to multi-turn conversations that reference
large spans of prior text. With LLAMA 4’s near-limitless context window, developers and researchers can
explore new frontiers in text generation and knowledge retrieval, enabling more nuanced, coherent, and
in-depth AI-driven interactions than ever before.
3. Better Fine-Tuning Options
LLAMA 4 introduces a more robust and user-friendly approach to fine-tuning. Thanks to an expanded set of APIs and support for popular machine learning frameworks, you can now customize the model for domain-specific applications more easily. The new fine-tuning pipeline also takes advantage of parallel processing, reducing the required training time and resources needed to achieve a reliable, domain-tailored model.
4. Improved Multi-Lingual Proficiency
Building on LLAMA’s reputation for supporting multiple languages, LLAMA 4 now offers enhanced performance across a broader set of languages and dialects. This wide coverage makes it ideal for global applications, from customer support chatbots and interactive translation tools to culturally nuanced content generation. The model’s improved ability to recognize subtle linguistic differences reduces mistranslation risk and improves overall reliability in multi-lingual contexts.
5. Optimized Code Generation and Reasoning
Developers and data scientists will appreciate how LLAMA 4 can assist in generating code snippets, debugging existing code, or analyzing code logic in a range of programming languages. It’s significantly better at ensuring the structural and logical consistency of generated code. Additionally, improved chain-of-thought reasoning features enable the model to walk through its logic more transparently, giving developers deeper insights into how it arrives at solutions.
6. Stronger Guardrails for Safe AI Usage
LLAMA 4 incorporates stronger guardrails aimed at minimizing harmful or biased outputs. Through a mix of curated data, improved filtering, and updates to its reinforcement learning from human feedback (RLHF) protocols, LLAMA 4 is designed to reduce the generation of offensive content. While no AI is perfect, these enhanced safeguards contribute to a more responsible and user-friendly model.
7. Low-Latency Inference
The developers behind LLAMA 4 have placed a strong emphasis on inference efficiency. This is the stage where the model is used for prediction or content generation once trained or fine-tuned. LLAMA 4’s architecture is better optimized to handle inference on GPUs or specialized AI chips with reduced latency. For applications that demand near real-time interactions—like live chatbots or dynamic content creation—this improvement is a significant advantage.
Llama 4: Leading Multimodal Intelligence. Behemoth, Scout, and Maverick
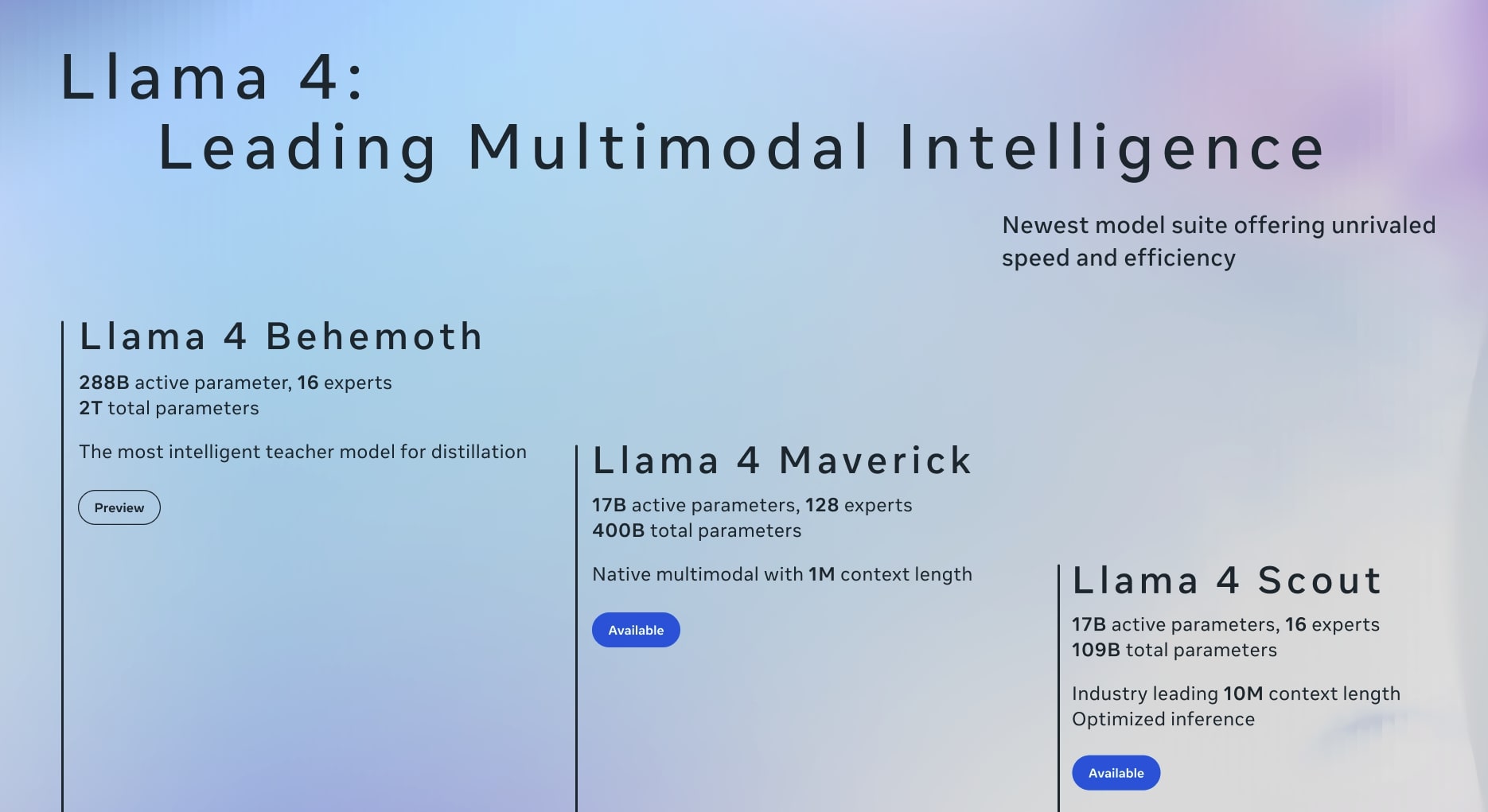
The newest Llama 4 model suite offers unrivaled speed, efficiency, and flexibility for a range of tasks, from
knowledge distillation to large-scale multimodal applications. Below is a quick overview of the three
specialized variants and what each one brings to the table.
Llama 4 Behemoth
288B active parameters, 16 experts • 2T total parameters
Designed as the most intelligent teacher model for distillation, Behemoth shines in scenarios requiring
extremely high model capacity and advanced reasoning. Its vast parameter count and expert layers make it
ideal for transferring deep knowledge to smaller models, accelerating research and development in large-scale
AI projects.
Llama 4 Maverick
17B active parameters, 128 experts • 400B total parameters
Featuring a native multimodal approach with up to 1M context length, Maverick excels at
handling complex tasks that span text, images, or other data types. Its extensive context window ensures
better long-form comprehension and nuanced responses, making it a powerful choice for developers who need
a model that can manage diverse and lengthy inputs with minimal compromises on performance.
Llama 4 Scout
17B active parameters, 16 experts • 109B total parameters
Offering an industry-leading 10M context length, Scout is optimized for ultra-long
sequence inference. Whether it’s analyzing vast documents, handling intricate multi-turn conversations,
or running extended simulations, its streamlined architecture focuses on delivering efficient and
scalable performance—even when working with immense sequences of data.
Benchmarks: Speed, Price, and Intelligence
Recent benchmarking results highlight how Llama 4 Maverick and Llama 4 Scout compare against a range of other
large language models. Three core metrics—speed, price, and intelligence—paint a clear picture of each model’s
strengths and potential trade-offs:
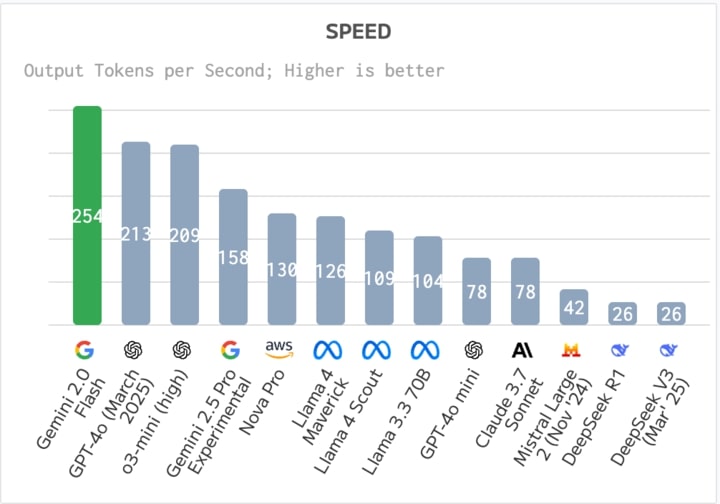
Speed
Measured in tokens per second, this metric indicates how quickly a model can generate output. Llama 4 Maverick
and Llama 4 Scout maintain competitive speeds compared to other state-of-the-art models, with Maverick achieving
around 126 tokens/second and Scout close behind at 109 tokens/second. Although some models like Gemini 2.0 Flash
or GPT-40 (March 2025) may achieve higher token outputs, both Maverick and Scout demonstrate a solid balance
between throughput and computational demands.
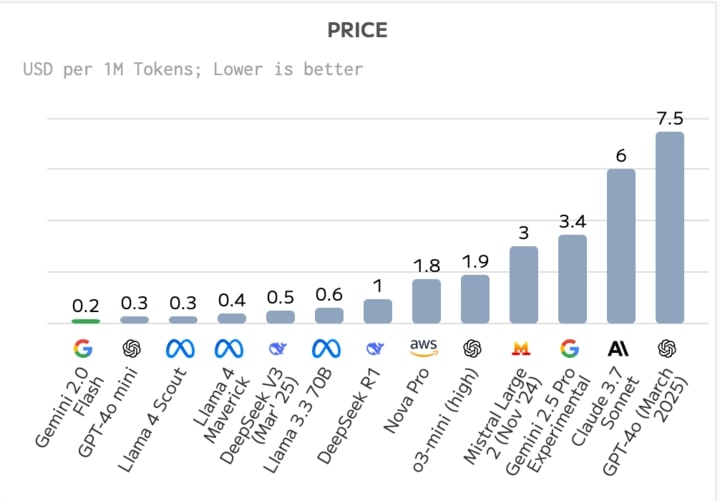
Price
This chart measures cost in USD per million tokens. Llama 4 Maverick and Llama 4 Scout stand out for their
relatively low cost among premium models, with Scout averaging $0.3 per million tokens and
Maverick around $0.4. In contexts where large-scale generation or inference is frequent—such
as content creation, analysis pipelines, or AI-driven customer support—these lower operating expenses can
translate to significant savings over time.
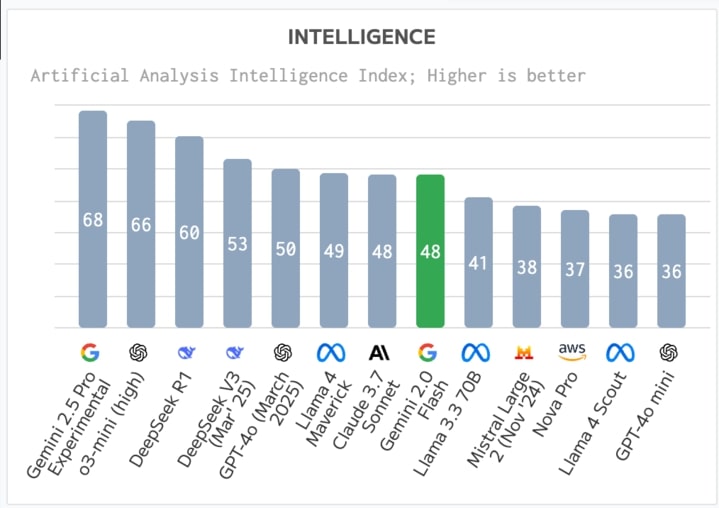
Intelligence
The “Artificial Analysis Intelligence Index” gauges a model’s ability to handle complex reasoning, contextual
awareness, and nuanced language tasks. With scores around the mid-to-high range (e.g., 49 for
Maverick and 36 for Scout), Llama 4 variants keep pace with other leading-edge solutions such
as Claude 3.7 and Somet. While some experimental or specialized models may top these metrics, Llama 4’s well-rounded
performance strikes a consistent balance between accuracy, speed, and affordability.
Overall, these benchmarks demonstrate that Llama 4 Maverick and Llama 4 Scout offer competitive performance,
cost-effectiveness, and intelligent reasoning compared to both established and emerging LLMs. Whether you
prioritize high throughput, budget-friendly operations, or robust analytical capabilities, Llama 4’s variants
deliver a versatile set of strengths for a broad range of use cases.
How to Run LLAMA 4 Locally on Your Machine
Running large language models locally has become increasingly accessible, offering greater control, improved data privacy, and reduced long-term costs. Below is a step-by-step guide on how to set up LLAMA 4 on your personal or professional workstation.
1. Prerequisites and Hardware Considerations
- GPU: At least one high-end GPU with sufficient VRAM (96GB or more) is recommended for smooth operation.
- RAM: Aim for a minimum of 32GB of system RAM, although 64GB or more may be needed for large-scale tasks.
- Storage: Ensure you have adequate SSD space (tens of GBs) to store the model weights and data. The model weight is about 207 GB.
- Operating System: Compatible with both Windows and Linux, with Linux often preferred for performance and stability.
2. Software Setup
Begin by installing a recent version of Python (3.8+) and create a virtual environment to keep dependencies organized. You’ll need popular ML frameworks like PyTorch or TensorFlow, alongside libraries such as Transformers and Accelerate. Make sure your NVIDIA drivers and CUDA toolkit are up to date for GPU-based systems.
python3 -m venv llama4_env
source llama4_env/bin/activate
pip install torch torchvision torchaudio transformers accelerate cuda-python
3. Obtain LLAMA 4 Model Weights
Download the LLAMA 4 model weights from an official source or a trusted repository, ensuring you have the necessary credentials if required. Place the weights in an accessible directory.
4. Load the Model
from transformers import LlamaForCausalLM, LlamaTokenizer
model_path = "path_to_llama4_model"
tokenizer = LlamaTokenizer.from_pretrained(model_path)
model = LlamaForCausalLM.from_pretrained(model_path, device_map="auto")
Adjust device_map (e.g., "cuda:0" or "cpu") based on your system. Use "auto" to automatically detect available GPUs.
5. Generate Text
prompt = "Explain the concept of transfer learning in AI:"
input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.device)
output = model.generate(
input_ids,
max_length=200,
temperature=0.7,
do_sample=True,
top_k=50,
top_p=0.95
)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
Experiment with parameters like max_length, temperature, top_k, and top_p to balance creativity and coherence.
6. Fine-Tuning (Optional)
Use frameworks like the Hugging Face Trainer API to tailor LLAMA 4 for specialized tasks. This requires a labeled dataset, ample GPU resources, and a solid understanding of hyperparameters. LLAMA 4’s refined architecture supports faster fine-tuning but demands powerful hardware for large-scale tasks.
Performance Tips
- Batching: Process multiple prompts together to improve GPU utilization.
- Mixed Precision: Use FP16 or BF16 to reduce memory usage and speed up computations.
- Model Parallelism: Distribute very large LLAMA 4 variants across multiple GPUs.
- Efficient Data Loading: Use pinned memory and parallel data loaders to minimize overhead.
Bizon Workstation Offerings for LLAMA 4
Harnessing the full potential of LLAMA 4 requires robust hardware solutions. While consumer-level GPUs can handle smaller models, Bizon workstations are purpose-built to manage large language models effectively, offering both reliability and top-tier performance.
Why Choose a Bizon Workstation?
- Optimized for Deep Learning: Pre-configured with NVIDIA GPUs, high-core-count CPUs, and efficient cooling solutions.
- Scalability: Options range from single-GPU workstations for lighter tasks to multi-GPU setups for massive training jobs.
- Reliability and Support: Dedicated tech support teams specialized in AI workflows can assist with troubleshooting and maintenance.
- Custom Configuration: Tailor CPU, GPU, RAM, and storage to your specific usage scenarios, from R&D to production-level deployments.
- Pre-Installed Software Stack: Systems can come with CUDA, cuDNN, PyTorch, TensorFlow, and other AI frameworks pre-installed.
Bizon Models for LLAMA 4
-
Bizon X5500

Engineered for extreme performance, the Bizon X5500 can accommodate up to two high-end GPUs, making it ideal for demanding AI/ML workloads, fine-tuning large language models like LLAMA 4, and handling VR development and 3D animation workflows. Its robust power and cooling solutions ensure reliable performance even under intensive loads.
-
Bizon ZX5500

Versatile and powerful, the Bizon ZX5500 shines in heavy computational tasks, including AI training, inference, and advanced LLM research. With support for multiple GPU configurations and a high-core-count CPU, it provides the flexibility and horsepower needed to quickly iterate on LLAMA 4-based solutions or large-scale deep learning projects.
-
Bizon ZX4000

Compact yet remarkably powerful, the Bizon ZX4000 is a perfect entry point for local AI training and inference. Its efficient footprint and thoughtful design enable you to deploy LLAMA 4 or other state-of-the-art models without sacrificing performance, making it an excellent choice for smaller office spaces or dedicated workstation setups.
Additional Considerations
Even if you’re starting with a single or dual-GPU configuration, it’s wise to plan for future expansion. LLAMA 4 and other emerging AI models are rapidly evolving, so choosing a chassis and motherboard with enough room for additional GPUs and RAM can save time and money in the long run.
- Cooling and Thermal Management: High-end GPUs and CPUs generate a lot of heat under sustained loads. Bizon’s custom cooling solutions ensure stable performance over long training sessions.
- Power Supply: Larger GPU setups require robust power supplies that can handle peak loads. Bizon’s workstations come equipped with reliable, high-wattage PSUs.
- Future Upgrade Paths: Select motherboards that support extra PCIe slots, more RAM, and the ability to add or swap out GPUs down the line.
Conclusion
LLAMA 4 represents a significant milestone in the world of generative AI, blending larger model sizes and extended context windows with user-friendly fine-tuning workflows and enhanced safety features. Whether you’re generating complex code snippets, analyzing multi-lingual texts, or orchestrating intelligent chatbots, LLAMA 4 sets a new performance standard.
Running LLAMA 4 locally grants you control over your data and workflow, while also potentially saving on cloud fees. By ensuring your system meets the necessary hardware requirements and optimizing for advanced features like mixed-precision inference and model parallelism, you can experience near real-time AI interactions and robust large-scale processing.
If you’re looking for a reliable and scalable hardware solution, Bizon workstations offer specialized options that simplify the process. From single-GPU setups for smaller workloads to multi-GPU powerhouses for high-end research and enterprise, Bizon’s configurations are purpose-built to support the demanding requirements of LLAMA 4 and other large language models. With professional support, upgrade-ready designs, and optimal cooling, Bizon ensures you can push your AI ambitions without worrying about hardware bottlenecks.
In this ever-evolving landscape of AI, harnessing the power of LLAMA 4 and the hardware that best suits it can accelerate innovation, streamline research, and revolutionize customer experiences. Don’t let hardware constraints limit your potential—explore Bizon’s range of deep learning workstations and unlock the full capabilities of LLAMA 4 in your own lab, office, or home environment.