Best GPU for deep learning in 2020: RTX 2080 Ti vs. TITAN RTX vs. RTX 6000 vs. RTX 8000 benchmarks (FP32, FP32 XLA, FP16, FP16 XLA)
By
Mark Stevens
February 29, 2020
AI / Deep learning
benchmarks
recommended GPU
AI, Deep Learning
Benchmarks
In this post, we are comparing the most popular graphics cards for deep learning in 2020: NVIDIA RTX 2080 Ti, Titan RTX, Quadro RTX 6000, and Quadro RTX 8000.
Test bench:

BIZON G3000 (4x GPU deep learning desktop)
More details: https://bizon-tech.com/bizon-g3000.html
Tech specs:
BIZON Z5000 (liquid cooled deep learning and GPU rendering workstation PC)
More details: https://bizon-tech.com/bizon-z5000.html

Tech specs:
Deep Learning Models:
Drivers and Batch Size:
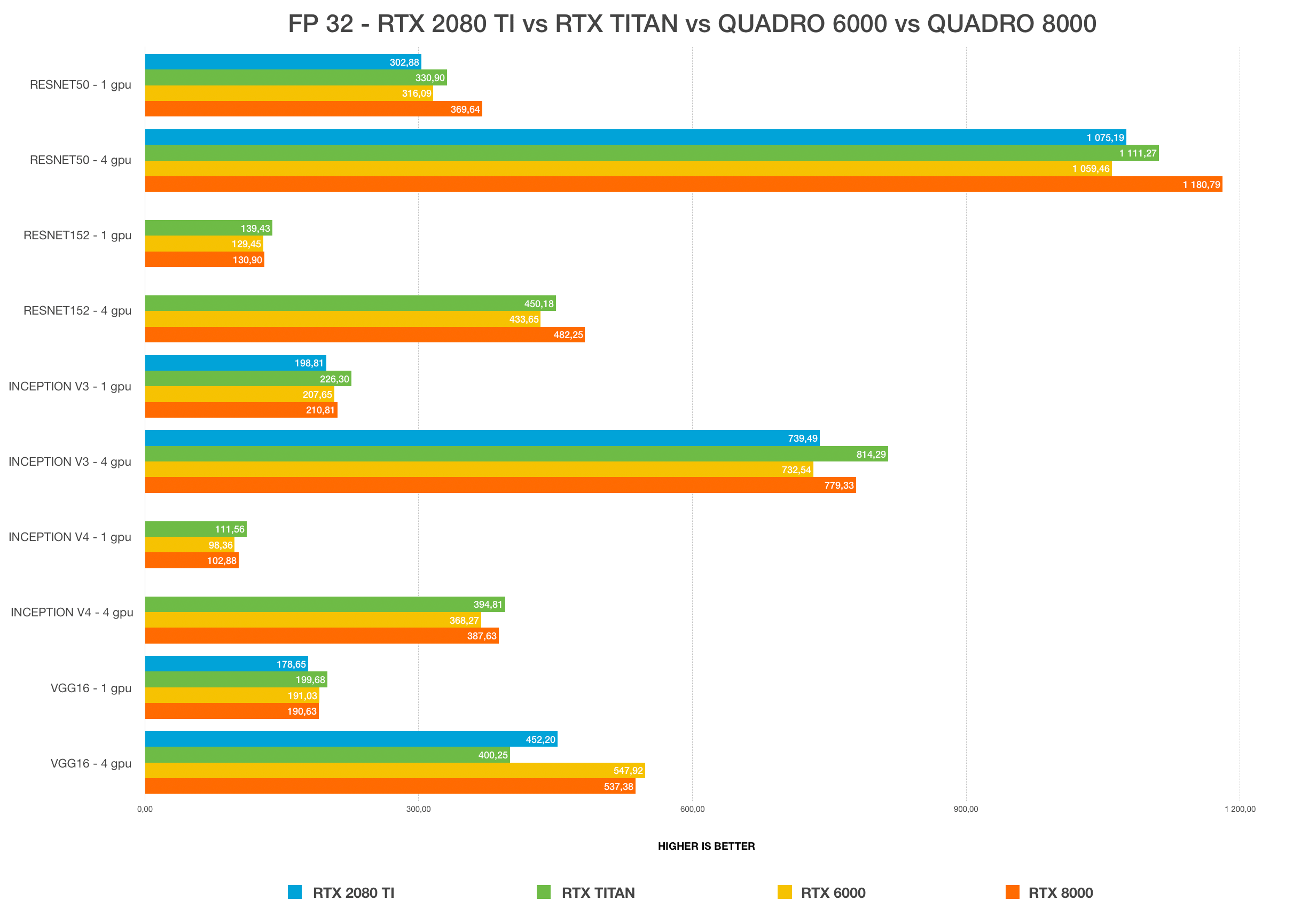
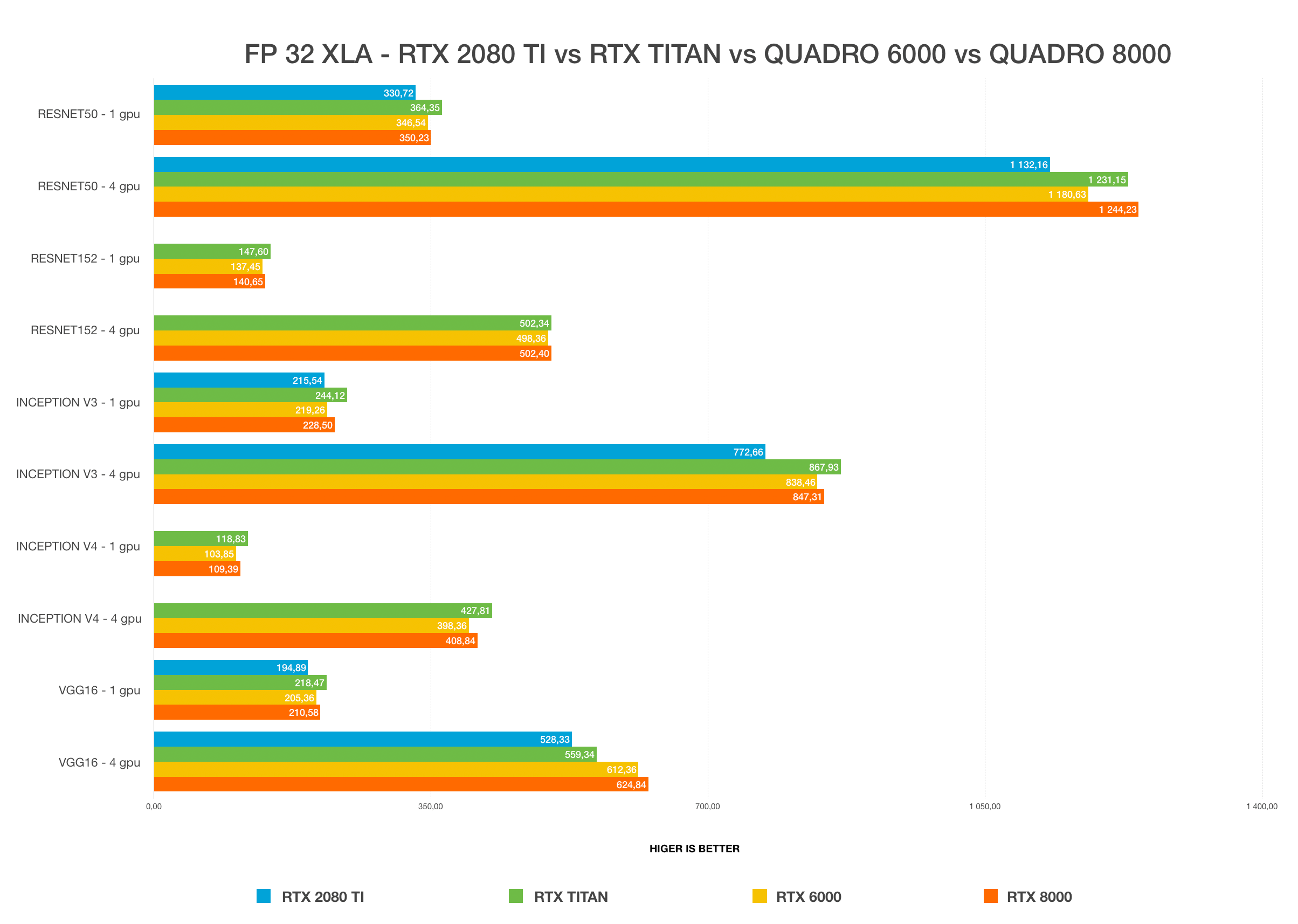
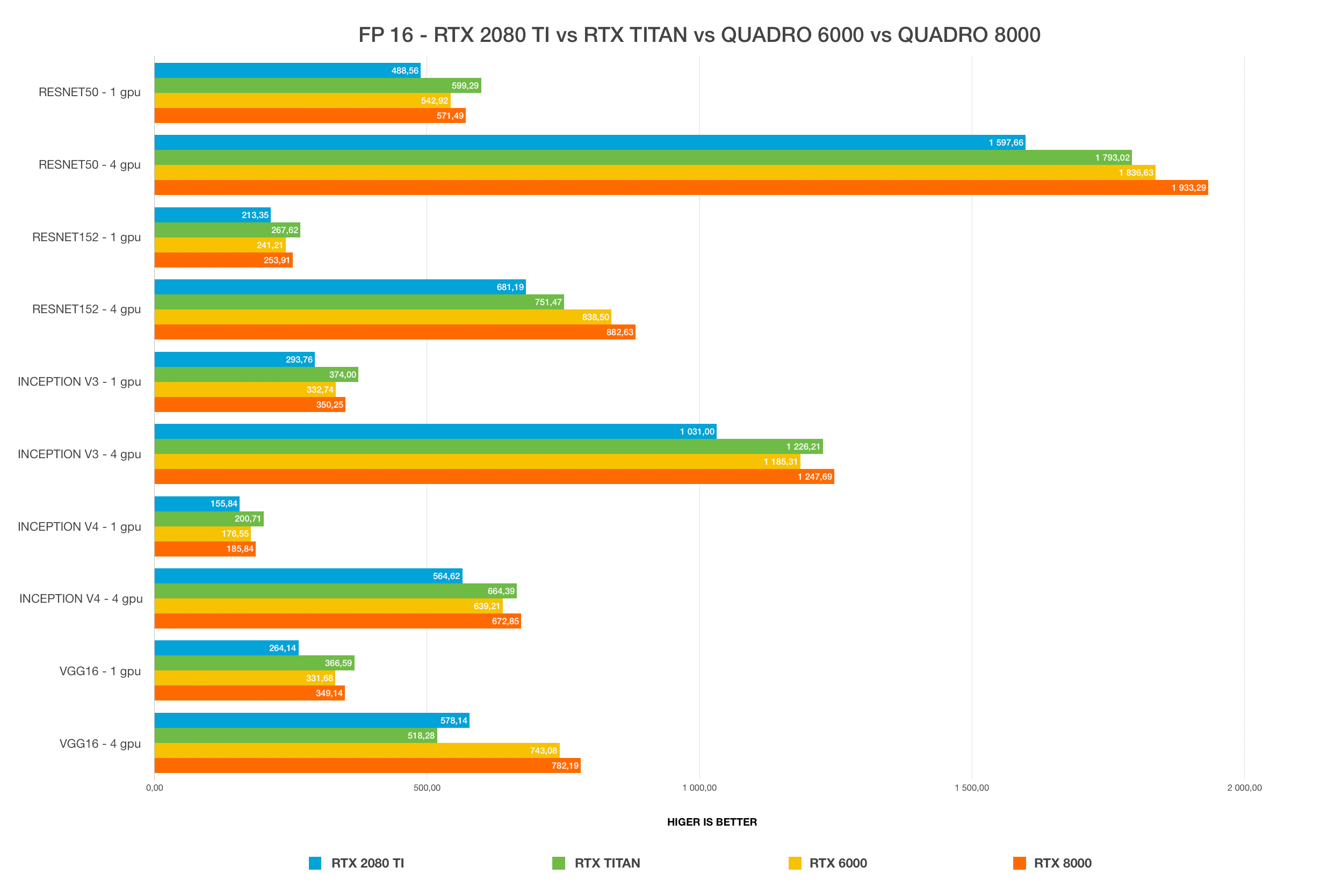
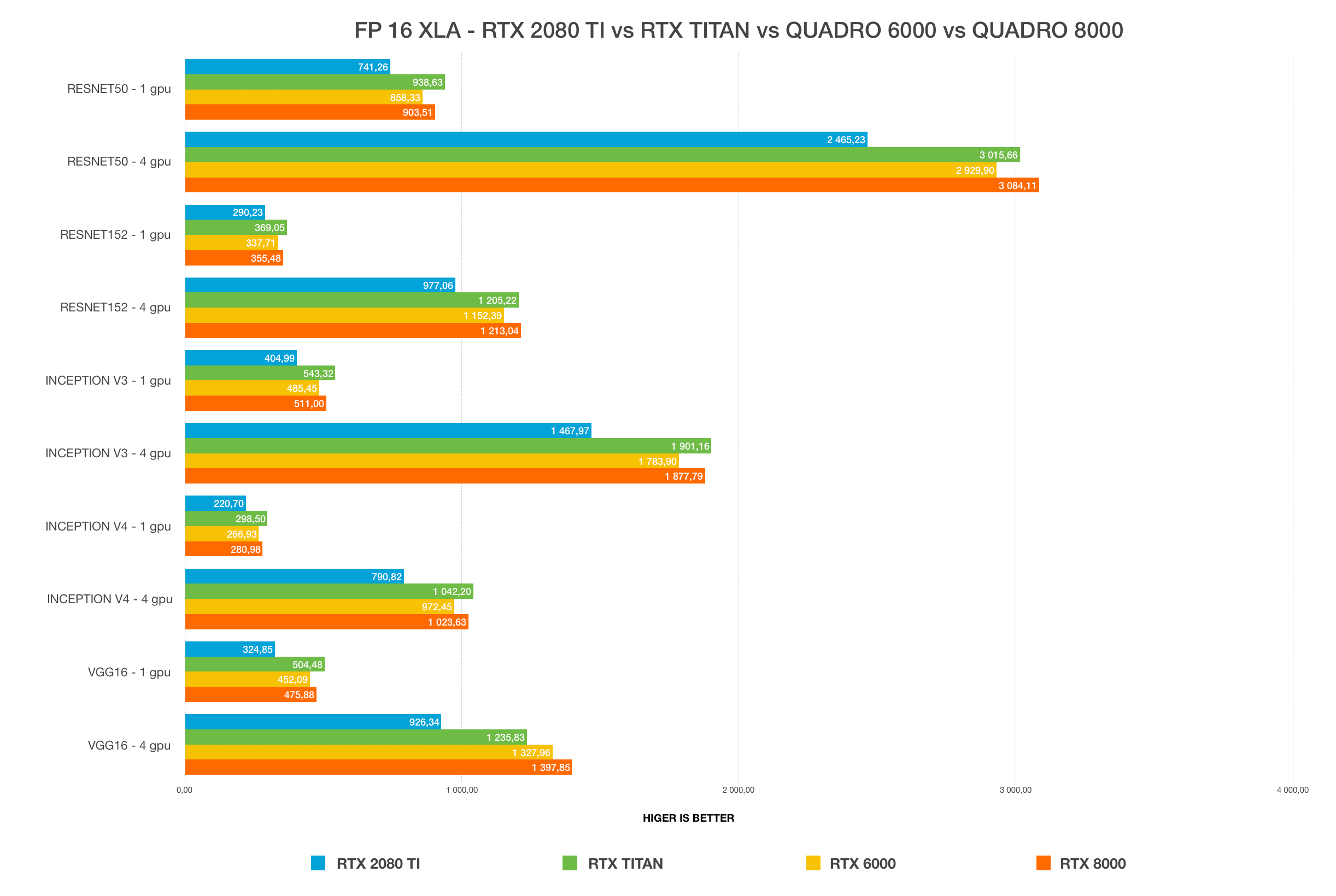
Winner: NVIDIA TITAN RTX, 24 GB
 Academic discounts are available.
Academic discounts are available.
Notes: Water-cooling required for 4 x TITAN RTX configurations. TITAN RTX will overheat immediately with air-cooling and will stop working.
The TITAN RTX is the best of two worlds: great performance and price. As you can see from the benchmarks, you get the performance close to Quadro RTX 8000 in most cases and 2X times lower price compared to RTX 8000.
When used as a pair with the NVLink bridge you have effectively 48 GB of memory to train large models.
The main problem of TITAN RTX is cooling. Since the Titan's are not the blower-fans they will immediately reach 90C and stop working (GPU will activate thermal throttling mode).
We have seen up to 60% (!) performance drop due to overheating. Liquid-cooling is the best solution. The liquid-cooling will provide 24/7 stability, low noise, long-life for components and you will get 100% performance out of the TITAN RTX. Per our tests, water-cooled TITAN RTX will keep in the safe range 50-50C vs 90C on air-cooling (90C is red zone when the GPU stop working and shutdown). Noise is another important point to mention. 4 x air-cooled GPUs are pretty noisy due to the blower-fans. Placing the workstation in the lab or office will be uncomfortable. Not to mention servers: the noise level is so hight that it’s almost impossible to speak when they are running.
Water-cooling solves the noise problem for desktops and servers. You get up to 20% lower noise vs. air cooling. You can easily run a workstation or even server with such huge computing power in the office or lab.
BIZON designed an enterprise-class custom liquid-cooling system for servers and workstations.
Recommended models:
We offer water-cooled 4 x GPU desktops and 10 x GPU servers with TITAN RTX:
RTX 2080 Ti, 11 GB (Blower Model)
 RTX 2080 Ti is an excellent GPU for deep learning and offer the best performance/price.
RTX 2080 Ti is an excellent GPU for deep learning and offer the best performance/price.
The main limitation is the VRAM size. Training on RTX 2080 Ti will require small batch sizes and in some cases, you will not be able to train large models. Using NVLINk will not combine the VRAM of multiple GPUs, unlike TITANs or Quadro.
Recommended models:
NVIDIA Quadro RTX 6000, 24 GB
 Academic discounts are available.
Academic discounts are available.
Quadro RTX offers the same memory capacity as TITAN RTX, plus the blower design.
Quadro RTX 8000, 48 GB
 Academic discounts are available.
Academic discounts are available.
Performance close to TITAN RTX. Recommended for extra large models since it comes with 48GB VRAM. When used in a pair w/NVLink you get 96GB of GPU memory. The price is the main disadvantage.
Recommended models:
For most users, the TITAN RTX or the RTX 2080 Ti will provide the best bang for the buck. The only limitation of 2080 Ti is 11 GB VRAM size. Working with a large batch size allows models to train faster and more accurately, saving a lot of time. This is only possible with Quadro GPUs and TITAN RTX. Using FP16 allows models to fit in the GPUs with insufficient VRAM size. In chart #1 and #2, the RTX 2080 Ti cannot fit models on Resnet-152 and inception-4 with FP32. Once we change it to FP16, it can fit perfectly. 24 GB VRAM on TITAN RTX is more than enough for most use cases and you can fit any model and use large batch sizes.
- We are using the standard “tf_cnn_benchmarks.py” benchmark script from official TensorFlow GitHub (more details).
- We ran tests on the following networks: ResNet-50, ResNet-152, Inception v3, Inception v4, VGG-16, AlexNet.
- We compared FP16 to FP32, FP16 XLA to FP32 XLA performance and used standard batch sizes (64 in most cases).
- We compared GPU scaling (1 GPU vs 4 GPUs).
- Please note: it is important to have the same drivers and frameworks versions installed on the workstation to get accurate results.
Test bench:
BIZON G3000 (4x GPU deep learning desktop)
More details: https://bizon-tech.com/bizon-g3000.html
Tech specs:
- CPU: Intel Core i9-9980XE 18-Core 3.00GHz
- Overclocking: Stage #3 +600 MHz (up to + 30% performance)
- Cooling: Liquid Cooling System (CPU; extra stability and low noise)
- Memory: 256 GB (6 x 32 GB) DDR4 3200 MHz
- Operating System: BIZON Z–Stack (Ubuntu 18.04 (Bionic) with preinstalled deep learning frameworks)
- HDD: 1TB PCIe SSD
- Network: 10 GBIT
BIZON Z5000 (liquid cooled deep learning and GPU rendering workstation PC)
More details: https://bizon-tech.com/bizon-z5000.html
Tech specs:
- CPU: Intel Core i9-9980XE 18-Core 3.00GHz
- Overclocking: Stage #3 +600 MHz (up to + 30% performance)
- Cooling: Custom water-cooling system (CPU + GPUs)
- Memory: 256 GB (6 x 32 GB) DDR4 3200 MHz
- Operating System: BIZON Z–Stack (Ubuntu 18.04 (Bionic) with preinstalled deep learning frameworks)
- HDD: 1TB PCIe SSD
- Network: 10 GBIT
Software
- Resnet50
- Resnet152
- Inception V3
- Inception V4
- VGG16
Drivers and Batch Size:
- Nvidia Driver: 440
- CUDA: 10.1
- TensorFlow: 1.14
- Batch size: 64
Winner: NVIDIA TITAN RTX, 24 GB
Price: $2500
Academic discounts are available.Notes: Water-cooling required for 4 x TITAN RTX configurations. TITAN RTX will overheat immediately with air-cooling and will stop working.
The TITAN RTX is the best of two worlds: great performance and price. As you can see from the benchmarks, you get the performance close to Quadro RTX 8000 in most cases and 2X times lower price compared to RTX 8000.
When used as a pair with the NVLink bridge you have effectively 48 GB of memory to train large models.
The main problem of TITAN RTX is cooling. Since the Titan's are not the blower-fans they will immediately reach 90C and stop working (GPU will activate thermal throttling mode).
We have seen up to 60% (!) performance drop due to overheating. Liquid-cooling is the best solution. The liquid-cooling will provide 24/7 stability, low noise, long-life for components and you will get 100% performance out of the TITAN RTX. Per our tests, water-cooled TITAN RTX will keep in the safe range 50-50C vs 90C on air-cooling (90C is red zone when the GPU stop working and shutdown). Noise is another important point to mention. 4 x air-cooled GPUs are pretty noisy due to the blower-fans. Placing the workstation in the lab or office will be uncomfortable. Not to mention servers: the noise level is so hight that it’s almost impossible to speak when they are running.
Water-cooling solves the noise problem for desktops and servers. You get up to 20% lower noise vs. air cooling. You can easily run a workstation or even server with such huge computing power in the office or lab.
BIZON designed an enterprise-class custom liquid-cooling system for servers and workstations.
Recommended models:
We offer water-cooled 4 x GPU desktops and 10 x GPU servers with TITAN RTX:
- BIZON Z5000 workstation(Core i9 + 4 x TITAN RTX)
- BIZON Z8000 workstation(Dual Xeon + 4 x TITAN RTX)
- BIZON Z9000 server (water-cooled 10 x TITAN RTX)
RTX 2080 Ti, 11 GB (Blower Model)
Price: $1200
RTX 2080 Ti is an excellent GPU for deep learning and offer the best performance/price.The main limitation is the VRAM size. Training on RTX 2080 Ti will require small batch sizes and in some cases, you will not be able to train large models. Using NVLINk will not combine the VRAM of multiple GPUs, unlike TITANs or Quadro.
Recommended models:
- BIZON G3000 workstation (Core i9 + 4 x RTX 2080 Ti)
- BIZON X5000 workstation (AMD Threadripper + 4 x RTX 2080 Ti)
- BIZON G7000 server (10 x RTX 2080 Ti)
NVIDIA Quadro RTX 6000, 24 GB
Price: $4000
Academic discounts are available.Quadro RTX offers the same memory capacity as TITAN RTX, plus the blower design.
Quadro RTX 8000, 48 GB
Price: $5500
Academic discounts are available.Performance close to TITAN RTX. Recommended for extra large models since it comes with 48GB VRAM. When used in a pair w/NVLink you get 96GB of GPU memory. The price is the main disadvantage.
Recommended models:
- BIZON G3000 workstation (Core i9 + 4 x Quadro RTX 6000, RTX 8000)
- BIZON X5000 workstation (AMD Threadripper + 4 x Quadro RTX 6000, RTX 8000)
- BIZON G7000 server (10 x Quadro RTX 6000, RTX 8000)
For most users, the TITAN RTX or the RTX 2080 Ti will provide the best bang for the buck. The only limitation of 2080 Ti is 11 GB VRAM size. Working with a large batch size allows models to train faster and more accurately, saving a lot of time. This is only possible with Quadro GPUs and TITAN RTX. Using FP16 allows models to fit in the GPUs with insufficient VRAM size. In chart #1 and #2, the RTX 2080 Ti cannot fit models on Resnet-152 and inception-4 with FP32. Once we change it to FP16, it can fit perfectly. 24 GB VRAM on TITAN RTX is more than enough for most use cases and you can fit any model and use large batch sizes.