Table of Contents
NVIDIA TITAN RTX Deep Learning Benchmarks 2019 – Performance improvements with XLA, AMP and NVLink in TensorFlow
In this post, we are going to benchmark the latest software and hardware features and see how they will affect the performance.
Latest software features are AMP (Automatic mixed precision) and XLA (Accelerated Linear Algebra).
Also, we will check how much performance increase we will get with and without NVLink bridge connected and how the batch size will affect the performance.
Test bench:
BIZON G7000 8 GPU deep learning server
More details: https://bizon-tech.com/bizon-g7000.html
Tech specs:
- CPU: Dual 18-Core 2.30 GHz Intel Xeon Gold 6140 (latest generation).
- Graphics cards: 4 x NVIDIA TITAN RTX
- 2 x NVLINK
- RAM: 256 DDR4 2666 MHz ECC.
- Storage: 1 TB PCIe SSD.
- NVIDIA drivers 418.56
- CUDA drivers: 10.1
- Model: Resnet50 v1.5
- Data: Synthetic
- Tensorflow: 1.14
- XLA, AMP, FP32 & FP16
- Batch size: 64 – 128
- Num iterations: 100
- Mode: Training_benchmark
Notes:
- Batch size:
NVIDIA RTX 2080 Ti support up to 64, TITAN RTX support up to 128. - AMP (Automatic mixed precision):
More info: https://devblogs.nvidia.com/nvidia-automatic-mixed-precision-tensorflow/ - XLA (Accelerated Linear Algebra):
More info: https://www.tensorflow.org/xla
Test 1: NVIDIA TITAN RTX Deep Learning Benchmarks:
No NVLink. Batch size: 64. XLA, AMP: on / off
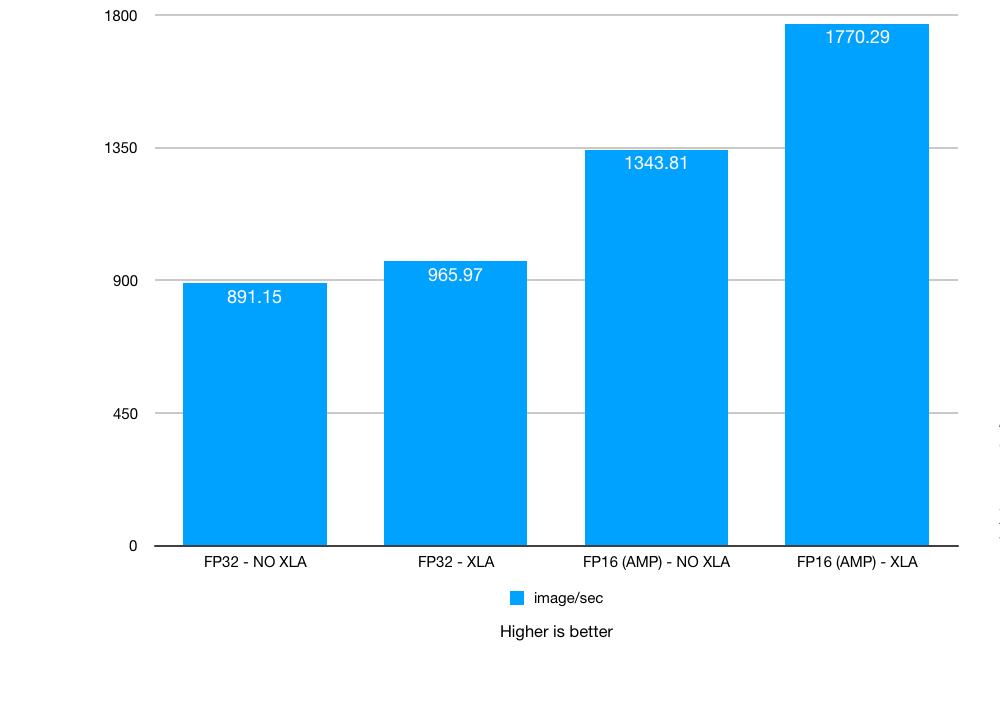
Test 2: NVIDIA TITAN RTX Deep Learning Benchmarks:
2 x NVLink. Batch size: 64. XLA, AMP: on / off
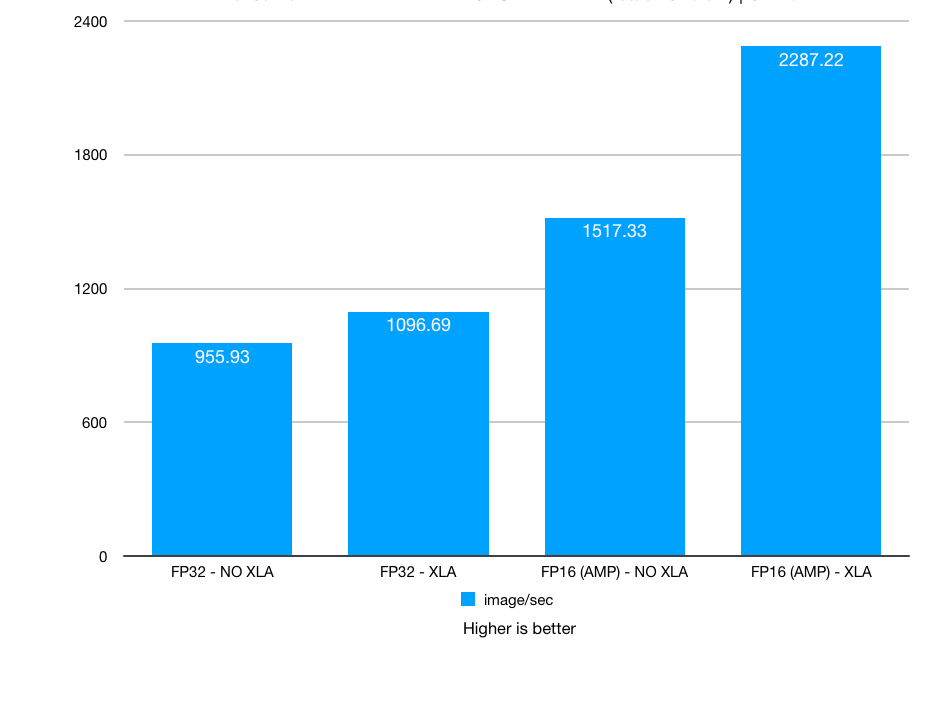
Test 3: NVIDIA TITAN RTX Deep Learning Benchmarks:
Overall chart. No NVLink vs. NVLink. Batch size: 64. XLA, AMP: on / off
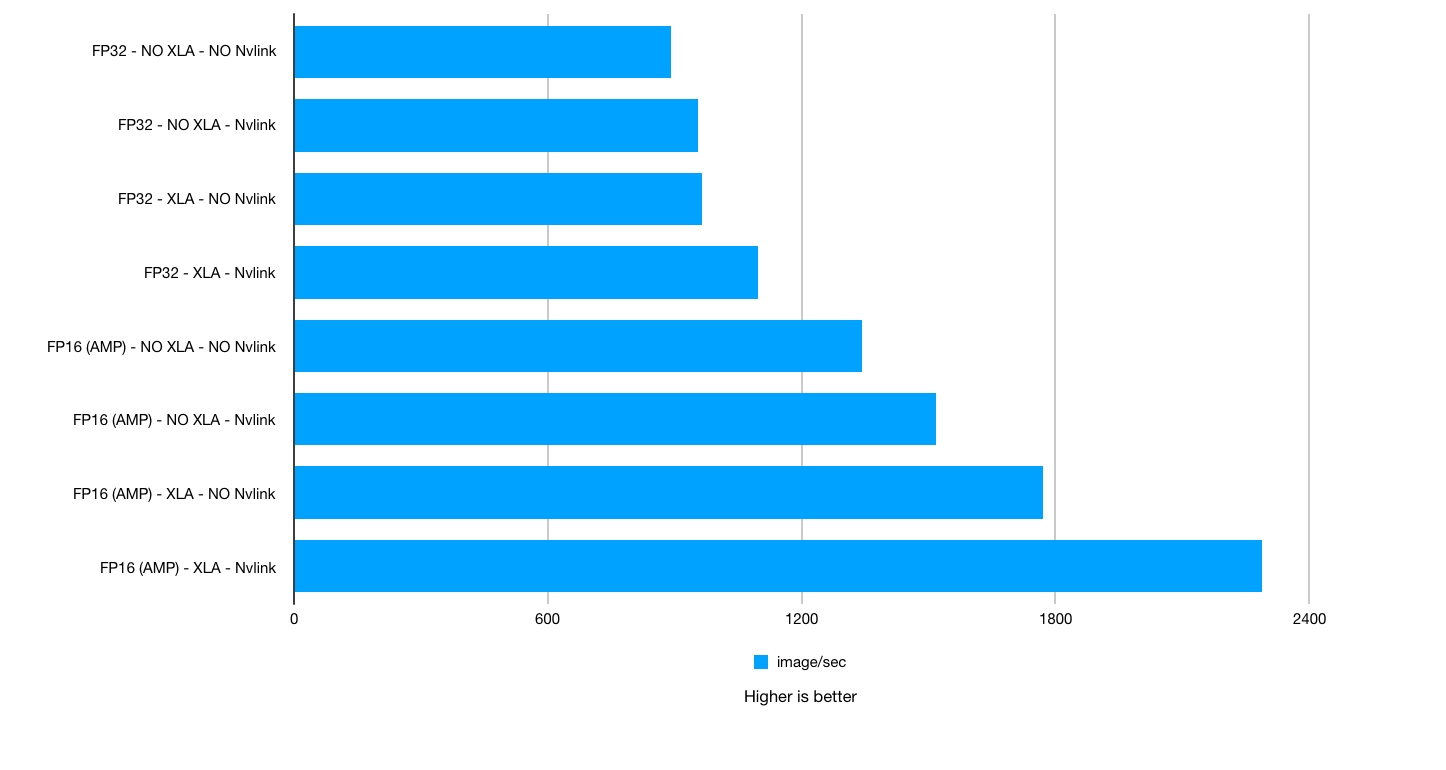
Test 4: NVIDIA TITAN RTX Deep Learning Benchmarks:
No NVLink. Batch size: 128. XLA, AMP: on / off
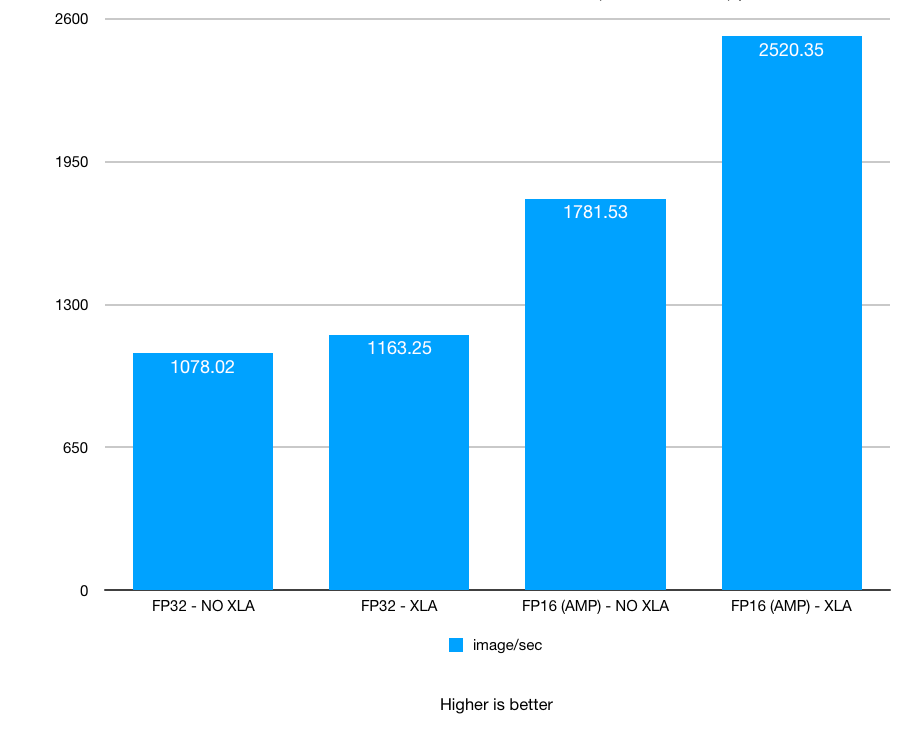
Test 5: NVIDIA TITAN RTX Deep Learning Benchmarks:
2 x NVLink. Batch size: 128. XLA, AMP: on / off
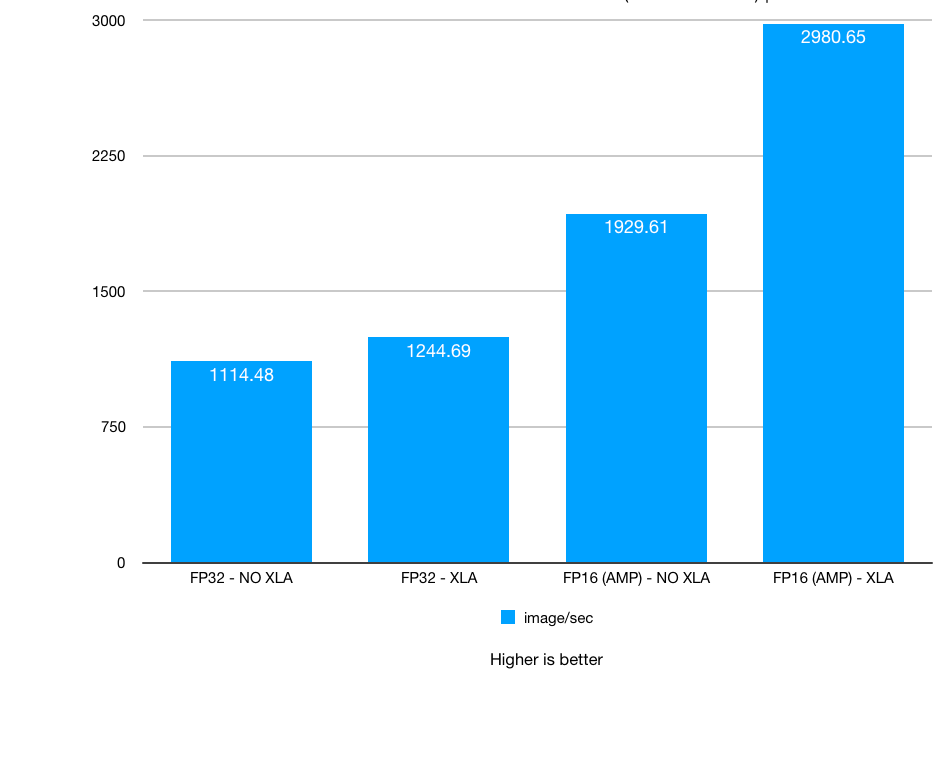
Test 6: NVIDIA TITAN RTX Deep Learning Benchmarks:
Overall chart. No NVLink vs. NVLink. Batch size: 128. XLA, AMP: on / off
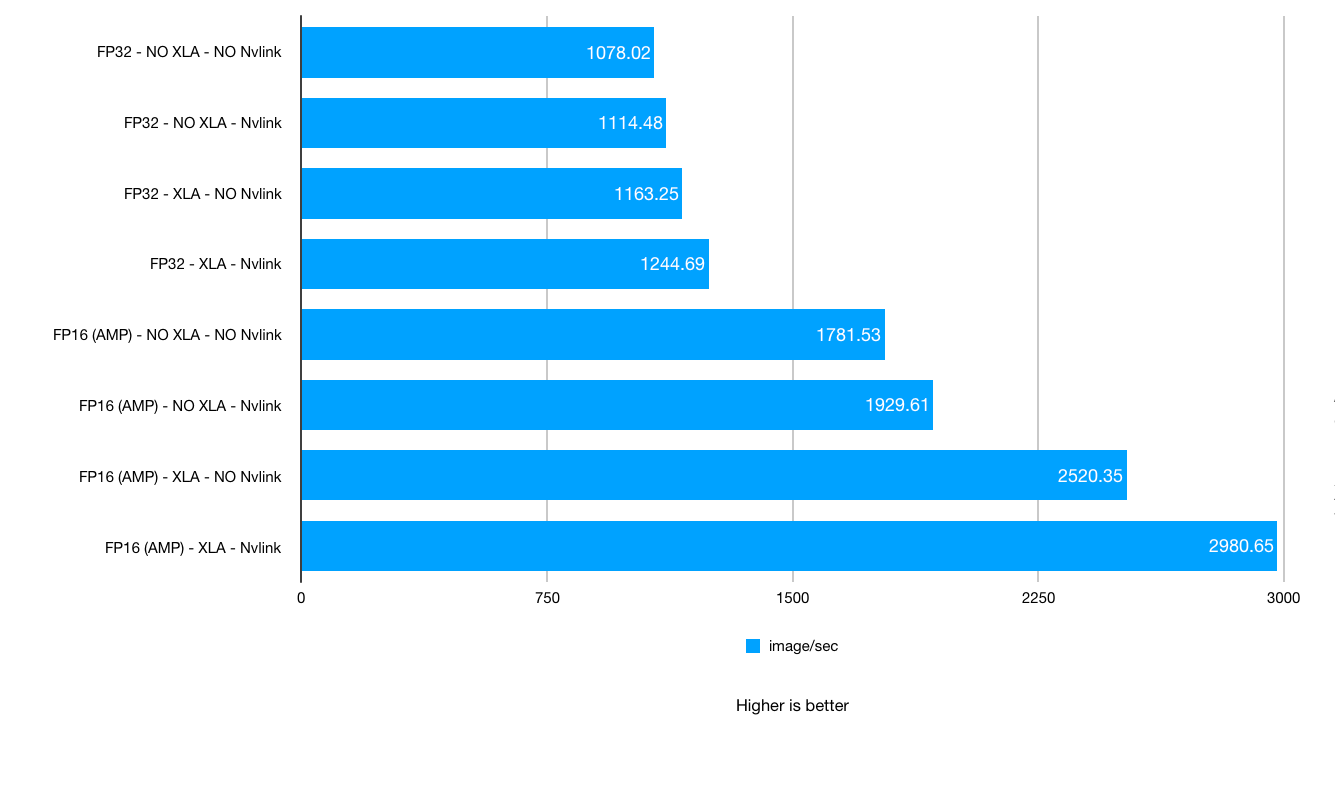
Test 7: NVIDIA TITAN RTX Deep Learning Benchmarks:
VRAM Usage. Batch size: 64 - 128. XLA, AMP: on / off
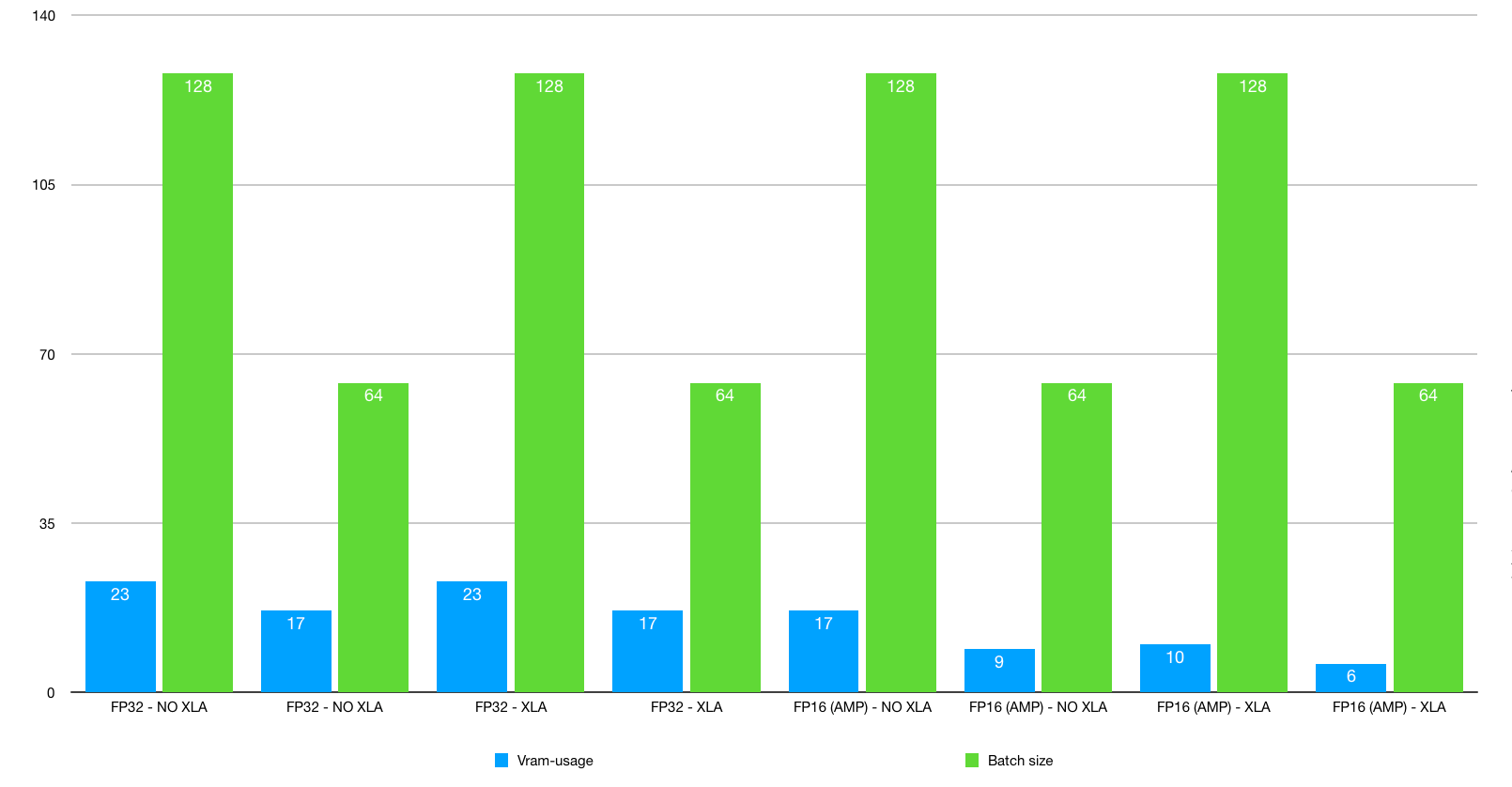
- NVLink significantly increases performance. We recommend making sure you add the NVLink when placing the order.
- Using bigger batch size increases performance. NVIDIA RTX 2080 Ti 11 GB cannot fit the large batch sizes and TITAN RTX 24 GB support up to 128 due to the VRAM size (11 GB vs. 24 GB).
- XLA significantly increases the amount of Img/sec.
All of the software and hardware features listed in this article are available for all BIZON deep learning workstations and servers. BIZON Stack comes with latest versions of Tensorflow and XLA, AMP support.